一般图最大匹配 带花树算法(Blossom Algorithm) 开花算法(Blossom Algorithm,也被称做带花树)可以解决一般图最大匹配问题(maximum cardinality matchings).此算法由 Jack Edmonds 在 1961 年提出. 经过一些修改后也可以解决一般图最大权匹配问题. 此算法是第一个给出证明说最大匹配有多项式复杂度.
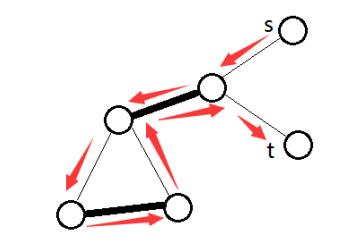
一般图匹配和二分图匹配(bipartite matching)不同的是,图可能存在奇环.
以此图为例,若直接取反(匹配边和未匹配边对调),会使得取反后的 𝑀 M
下面考虑一般图的增广算法. 从二分图的角度出发,每次枚举一个未匹配点,设出发点为根,标记为 「o」 ,接下来交错标记 「o」 和 「i」 ,不难发现 「i」 到 「o」 这段边是匹配边.
假设当前点是 𝑣 v 𝑢 u
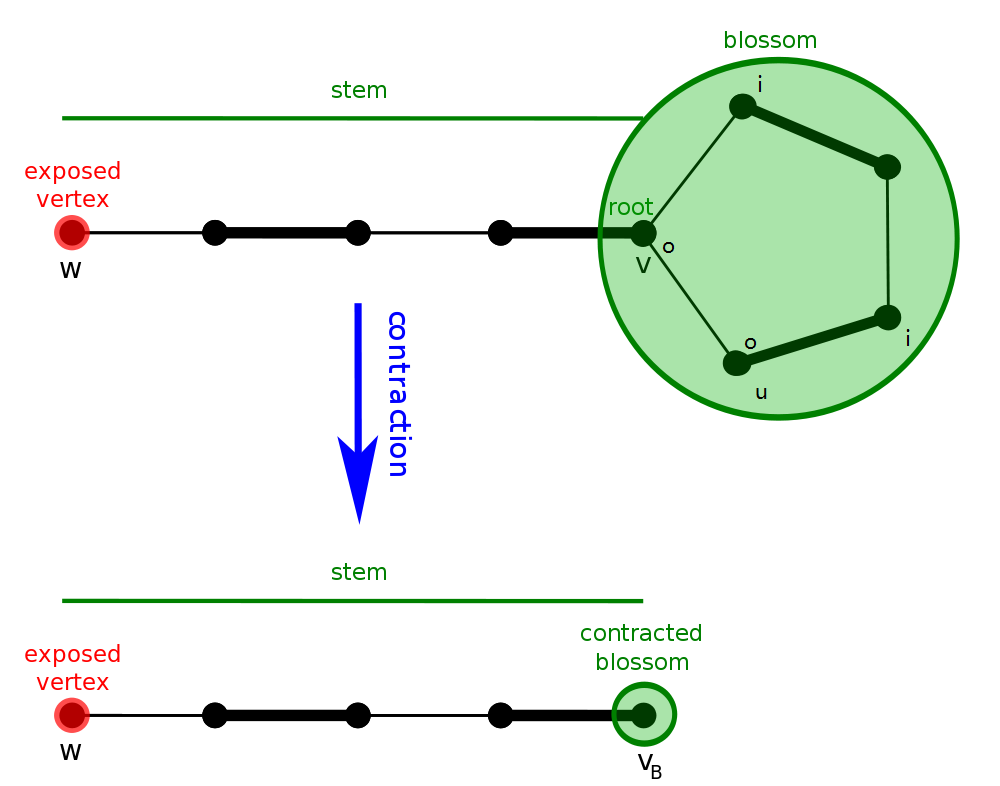
𝑢 u 𝑢 u 𝑢 u 𝑢 u 缩花 ,否则代表遇到偶环,跳过.遇到偶环的情况,将他视为二分图解决,故可忽略.缩花 后,再新图中继续找增广路.
设原图为 𝐺 G 缩花 后的图为 𝐺 ′ G ′
若 𝐺 G 𝐺 ′ G ′ 若 𝐺 ′ G ′ 𝐺 G
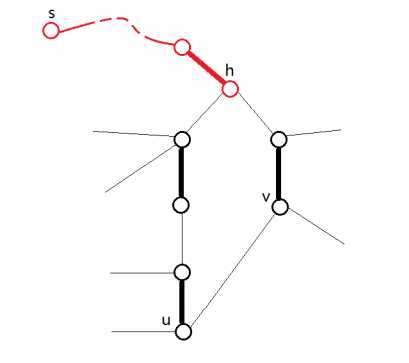
设非树边(形成环的那条边)为 ( 𝑢 , 𝑣 ) ( u , v ) ℎ = 𝐿 𝐶 𝐴 ( 𝑢 , 𝑣 ) h = L C A ( u , v ) ℎ h ℎ h ℎ h
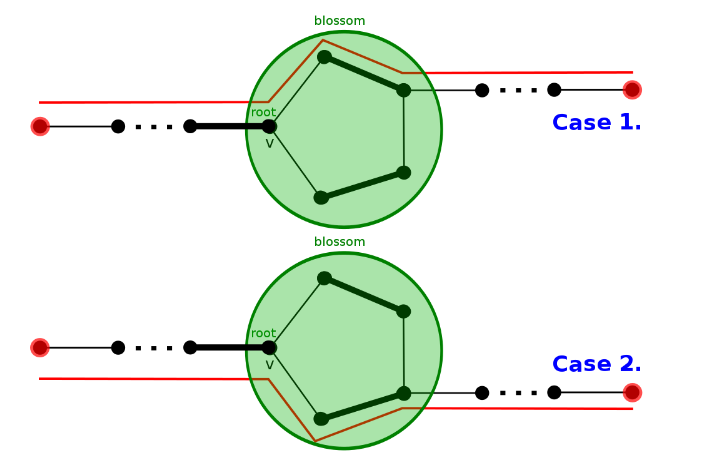
观察可知,从环外的边出去有两种情况,顺时针或逆时针.
于是 缩花 与 不缩花 都不影响正确性.
实作上找到 花 以后我们不需要真的 缩花 ,可以用数组纪录每个点在以哪个点为根的那朵花中.
复杂度分析 Complexity Analysis 每次找增广路,遍历所有边,遇到 花 会维护 花 上的点,𝑂 ( | 𝐸 | 2 ) O ( | E | 2 )
枚举所有未匹配点做增广路,总共 𝑂 ( | 𝑉 | | 𝐸 | 2 ) O ( | V | | E | 2 )
参考代码 参考代码 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162 // graph
template < typename T >
class graph {
public :
struct edge {
int from ;
int to ;
T cost ;
};
vector < edge > edges ;
vector < vector < int >> g ;
int n ;
graph ( int _n ) : n ( _n ) { g . resize ( n ); }
virtual int add ( int from , int to , T cost ) = 0 ;
};
// undirectedgraph
template < typename T >
class undirectedgraph : public graph < T > {
public :
using graph < T >:: edges ;
using graph < T >:: g ;
using graph < T >:: n ;
undirectedgraph ( int _n ) : graph < T > ( _n ) {}
int add ( int from , int to , T cost = 1 ) {
assert ( 0 <= from && from < n && 0 <= to && to < n );
int id = ( int ) edges . size ();
g [ from ]. push_back ( id );
g [ to ]. push_back ( id );
edges . push_back ({ from , to , cost });
return id ;
}
};
// blossom / find_max_unweighted_matching
template < typename T >
vector < int > find_max_unweighted_matching ( const undirectedgraph < T > & g ) {
std :: mt19937 rng ( std :: random_device {}());
vector < int > match ( g . n , -1 ); // 匹配
vector < int > aux ( g . n , -1 ); // 时间戳记
vector < int > label ( g . n ); // 「o」或「i」
vector < int > orig ( g . n ); // 花根
vector < int > parent ( g . n , -1 ); // 父节点
queue < int > q ;
int aux_time = -1 ;
auto lca = [ & ]( int v , int u ) {
aux_time ++ ;
while ( true ) {
if ( v != -1 ) {
if ( aux [ v ] == aux_time ) { // 找到拜访过的点 也就是LCA
return v ;
}
aux [ v ] = aux_time ;
if ( match [ v ] == -1 ) {
v = -1 ;
} else {
v = orig [ parent [ match [ v ]]]; // 以匹配点的父节点继续寻找
}
}
swap ( v , u );
}
}; // lca
auto blossom = [ & ]( int v , int u , int a ) {
while ( orig [ v ] != a ) {
parent [ v ] = u ;
u = match [ v ];
if ( label [ u ] == 1 ) { // 初始点设为「o」找增广路
label [ u ] = 0 ;
q . push ( u );
}
orig [ v ] = orig [ u ] = a ; // 缩花
v = parent [ u ];
}
}; // blossom
auto augment = [ & ]( int v ) {
while ( v != -1 ) {
int pv = parent [ v ];
int next_v = match [ pv ];
match [ v ] = pv ;
match [ pv ] = v ;
v = next_v ;
}
}; // augment
auto bfs = [ & ]( int root ) {
fill ( label . begin (), label . end (), -1 );
iota ( orig . begin (), orig . end (), 0 );
while ( ! q . empty ()) {
q . pop ();
}
q . push ( root );
// 初始点设为「o」,这里以「0」代替「o」,「1」代替「i」
label [ root ] = 0 ;
while ( ! q . empty ()) {
int v = q . front ();
q . pop ();
for ( int id : g . g [ v ]) {
auto & e = g . edges [ id ];
int u = e . from ^ e . to ^ v ;
if ( label [ u ] == -1 ) { // 找到未拜访点
label [ u ] = 1 ; // 标记「i」
parent [ u ] = v ;
if ( match [ u ] == -1 ) { // 找到未匹配点
augment ( u ); // 寻找增广路径
return true ;
}
// 找到已匹配点 将与她匹配的点丢入queue 延伸交错树
label [ match [ u ]] = 0 ;
q . push ( match [ u ]);
continue ;
} else if ( label [ u ] == 0 && orig [ v ] != orig [ u ]) {
// 找到已拜访点 且标记同为「o」代表找到「花」
int a = lca ( orig [ v ], orig [ u ]);
// 找LCA 然后缩花
blossom ( u , v , a );
blossom ( v , u , a );
}
}
}
return false ;
}; // bfs
auto greedy = [ & ]() {
vector < int > order ( g . n );
// 随机打乱 order
iota ( order . begin (), order . end (), 0 );
shuffle ( order . begin (), order . end (), rng );
// 将可以匹配的点匹配
for ( int i : order ) {
if ( match [ i ] == -1 ) {
for ( auto id : g . g [ i ]) {
auto & e = g . edges [ id ];
int to = e . from ^ e . to ^ i ;
if ( match [ to ] == -1 ) {
match [ i ] = to ;
match [ to ] = i ;
break ;
}
}
}
}
}; // greedy
// 一开始先随机匹配
greedy ();
// 对未匹配点找增广路
for ( int i = 0 ; i < g . n ; i ++ ) {
if ( match [ i ] == -1 ) {
bfs ( i );
}
}
return match ;
}
UOJ #79. 一般图最大匹配 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197 #include <algorithm>
#include <cassert>
#include <iostream>
#include <numeric>
#include <queue>
#include <random>
#include <vector>
using namespace std ;
// graph
template < typename T >
class graph {
public :
struct edge {
int from ;
int to ;
T cost ;
};
vector < edge > edges ;
vector < vector < int >> g ;
int n ;
graph ( int _n ) : n ( _n ) { g . resize ( n ); }
virtual int add ( int from , int to , T cost ) = 0 ;
};
// undirectedgraph
template < typename T >
class undirectedgraph : public graph < T > {
public :
using graph < T >:: edges ;
using graph < T >:: g ;
using graph < T >:: n ;
undirectedgraph ( int _n ) : graph < T > ( _n ) {}
int add ( int from , int to , T cost = 1 ) {
assert ( 0 <= from && from < n && 0 <= to && to < n );
int id = ( int ) edges . size ();
g [ from ]. push_back ( id );
g [ to ]. push_back ( id );
edges . push_back ({ from , to , cost });
return id ;
}
};
// blossom / find_max_unweighted_matching
template < typename T >
vector < int > find_max_unweighted_matching ( const undirectedgraph < T > & g ) {
std :: mt19937 rng ( 114514 ); // 这里随机种子是无关紧要的
// 也可以用 chrono::steady_clock::now().time_since_epoch().count()
// 获取当前时间
vector < int > match ( g . n , -1 ); // 匹配
vector < int > aux ( g . n , -1 ); // 时间戳记
vector < int > label ( g . n ); // "o" or "i"
vector < int > orig ( g . n ); // 花根
vector < int > parent ( g . n , -1 ); // 父节点
queue < int > q ;
int aux_time = -1 ;
auto lca = [ & ]( int v , int u ) {
aux_time ++ ;
while ( true ) {
if ( v != -1 ) {
if ( aux [ v ] == aux_time ) { // 找到拜访过的点 也就是LCA
return v ;
}
aux [ v ] = aux_time ;
if ( match [ v ] == -1 ) {
v = -1 ;
} else {
v = orig [ parent [ match [ v ]]]; // 以匹配点的父节点继续寻找
}
}
swap ( v , u );
}
}; // lca
auto blossom = [ & ]( int v , int u , int a ) {
while ( orig [ v ] != a ) {
parent [ v ] = u ;
u = match [ v ];
if ( label [ u ] == 1 ) { // 初始点设为"o" 找增广路
label [ u ] = 0 ;
q . push ( u );
}
orig [ v ] = orig [ u ] = a ; // 缩花
v = parent [ u ];
}
}; // blossom
auto augment = [ & ]( int v ) {
while ( v != -1 ) {
int pv = parent [ v ];
int next_v = match [ pv ];
match [ v ] = pv ;
match [ pv ] = v ;
v = next_v ;
}
}; // augment
auto bfs = [ & ]( int root ) {
fill ( label . begin (), label . end (), -1 );
iota ( orig . begin (), orig . end (), 0 );
while ( ! q . empty ()) {
q . pop ();
}
q . push ( root );
// 初始点设为 "o", 这里以"0"代替"o", "1"代替"i"
label [ root ] = 0 ;
while ( ! q . empty ()) {
int v = q . front ();
q . pop ();
for ( int id : g . g [ v ]) {
auto & e = g . edges [ id ];
int u = e . from ^ e . to ^ v ;
if ( label [ u ] == -1 ) { // 找到未拜访点
label [ u ] = 1 ; // 标记 "i"
parent [ u ] = v ;
if ( match [ u ] == -1 ) { // 找到未匹配点
augment ( u ); // 寻找增广路径
return true ;
}
// 找到已匹配点 将与她匹配的点丢入queue 延伸交错树
label [ match [ u ]] = 0 ;
q . push ( match [ u ]);
continue ;
} else if ( label [ u ] == 0 && orig [ v ] != orig [ u ]) {
// 找到已拜访点 且标记同为"o" 代表找到"花"
int a = lca ( orig [ v ], orig [ u ]);
// 找LCA 然后缩花
blossom ( u , v , a );
blossom ( v , u , a );
}
}
}
return false ;
}; // bfs
auto greedy = [ & ]() {
vector < int > order ( g . n );
// 随机打乱 order
iota ( order . begin (), order . end (), 0 );
shuffle ( order . begin (), order . end (), rng );
// 将可以匹配的点匹配
for ( int i : order ) {
if ( match [ i ] == -1 ) {
for ( auto id : g . g [ i ]) {
auto & e = g . edges [ id ];
int to = e . from ^ e . to ^ i ;
if ( match [ to ] == -1 ) {
match [ i ] = to ;
match [ to ] = i ;
break ;
}
}
}
}
}; // greedy
// 一开始先随机匹配
greedy ();
// 对未匹配点找增广路
for ( int i = 0 ; i < g . n ; i ++ ) {
if ( match [ i ] == -1 ) {
bfs ( i );
}
}
return match ;
}
int main () {
ios :: sync_with_stdio ( false );
int n , m ;
cin >> n >> m ;
undirectedgraph < int > g ( n );
while ( m -- ) {
int u , v ;
cin >> u >> v ;
g . add ( u - 1 , v - 1 ); // 0-based
}
auto match = find_max_unweighted_matching ( g );
cout << count_if ( match . begin (), match . end (), []( int x ) { return x != -1 ; }) /
2
<< endl ;
for ( int i = 0 ; i < n ; i ++ ) cout << match [ i ] + 1 << " \n " [ i == n - 1 ];
return 0 ;
}
基于高斯消元的一般图匹配算法 提示 在阅读以下内容前,你可能需要先阅读「线性代数」部分中关于矩阵的内容:
这一部分将介绍一种基于高斯消元的一般图匹配算法.与传统的带花树算法相比,它的优势在于更易于理解与编写,同时便于解决「最大匹配中的必须点」等问题;缺点在于常数比较大,因为高斯消元的 𝑂 ( 𝑛 3 ) O ( n 3 )
前置知识:Tutte 矩阵 定义 :对于一张 𝑛 n 𝐺 = ( 𝑉 , 𝐸 ) G = ( V , E ) ˜ 𝐴 ( 𝐺 ) A ~ ( G ) 𝑛 × 𝑛 n × n
˜ 𝐴 ( 𝐺 ) 𝑖 , 𝑗 = ⎧ { { ⎨ { { ⎩ 𝑥 𝑖 , 𝑗 , 𝑖 < 𝑗 , ( 𝑣 𝑖 , 𝑣 𝑗 ) ∈ 𝐸 − 𝑥 𝑖 , 𝑗 , 𝑖 > 𝑗 , ( 𝑣 𝑖 , 𝑣 𝑗 ) ∈ 𝐸 0 , o t h e r w i s e A ~ ( G ) i , j = { x i , j , i < j , ( v i , v j ) ∈ E − x i , j , i > j , ( v i , v j ) ∈ E 0 , otherwise 其中 𝑥 𝑖 , 𝑗 x i , j ˜ 𝐴 ( 𝐺 ) A ~ ( G ) | 𝐸 | | E |
在无歧义的情况下,以下将 ˜ 𝐴 ( 𝐺 ) A ~ ( G ) ˜ 𝐴 A ~
定理 (Tutte 定理):𝐺 G d e t ˜ 𝐴 ≠ 0 det A ~ ≠ 0
证明 这里引入「偶环覆盖」的概念:一个无向图 𝐺 G
易证 𝐺 G 𝐺 G
如果 𝐺 G 如果 𝐺 G 然后证明 𝐺 G ˜ 𝐴 ≠ 0 A ~ ≠ 0
考虑行列式的定义
d e t 𝐴 = ∑ 𝜋 ( − 1 ) 𝜋 ∏ 𝑖 𝐴 𝑖 , 𝜋 𝑖 det A = ∑ π ( − 1 ) π ∏ i A i , π i 其中 𝜋 π ( − 1 ) 𝜋 ( − 1 ) π 𝜋 π − 1 − 1 1 1
不难看出每个排列都可以被看作 𝐺 G 0 0 0 0
定理 :r a n k ˜ 𝐴 rank A ~ 𝐺 G r a n k ˜ 𝐴 rank A ~
证明 反对称矩阵的秩只能是偶数;后者请读者自行思考.
实际应用中不可能带着 | 𝐸 | | E | 𝑝 p Z 𝑝 Z p Z 𝑝 Z p ˜ 𝐴 A ~
定理 :r a n k ˜ 𝐴 rank A ~ 𝐺 G 1 − 𝑛 𝑝 1 − n p
考虑到一般图最大匹配中 𝑛 n 1 0 3 10 3 𝑝 p 1 0 9 10 9
由定理可知,如果只需要求最大匹配数,而无需匹配方案,那么只需要用一次高斯消元求出 r a n k ˜ 𝐴 rank A ~
构造完美匹配 由 Tutte 定理和上面的定理可知,如果 𝐺 G ˜ 𝐴 A ~
记 𝐺 G 𝑖 i 𝑣 𝑖 v i
定理 :˜ 𝐴 − 1 𝑗 , 𝑖 ≠ 0 ⟺ 𝐺 − { 𝑣 𝑖 , 𝑣 𝑗 } A ~ j , i − 1 ≠ 0 ⟺ G − { v i , v j }
逆矩阵与伴随矩阵 对任意 𝑛 n 𝐴 A 𝐴 ∗ 𝑖 , 𝑗 = ( − 1 ) 𝑖 + 𝑗 𝑀 𝑗 , 𝑖 A i , j ∗ = ( − 1 ) i + j M j , i 𝑀 𝑗 , 𝑖 M j , i 𝑗 j 𝑖 i 𝐴 A 𝑀 M 𝐴 ∗ = 𝑀 𝑇 A ∗ = M T
定理 :如果 𝐴 A 𝐴 − 1 = 1 d e t 𝐴 𝐴 ∗ A − 1 = 1 det A A ∗
所以这里的 𝐴 − 1 𝑗 , 𝑖 ≠ 0 ⟺ 𝑀 𝑖 , 𝑗 ≠ 0 A j , i − 1 ≠ 0 ⟺ M i , j ≠ 0 𝐴 A 𝑖 i 𝑗 j
换言之,如果 ( 𝑣 𝑖 , 𝑣 𝑗 ) ∈ 𝐸 ( v i , v j ) ∈ E ˜ 𝐴 − 1 𝑗 , 𝑖 ≠ 0 A ~ j , i − 1 ≠ 0 ( 𝑣 𝑖 , 𝑣 𝑗 ) ( v i , v j ) 可行边 .
由如上定理,对于一个有完美匹配的无向图 𝐺 G 𝑖 , 𝑗 i , j ( 𝑣 𝑖 , 𝑣 𝑗 ) ( v i , v j ) ˜ 𝐴 − 1 𝑗 , 𝑖 ≠ 0 A ~ j , i − 1 ≠ 0 ( 𝑣 𝑖 , 𝑣 𝑗 ) ( v i , v j ) 𝐺 G ˜ 𝐴 − 1 A ~ − 1
总共要做 𝑛 2 n 2 𝑂 ( 𝑛 3 ) O ( n 3 ) 𝑂 ( 𝑛 4 ) O ( n 4 ) ˜ 𝐴 − 1 A ~ − 1
定理 (消去定理):令
𝐴 = [ 𝑎 1 , 1 𝑣 𝑇 𝑢 𝐵 ] 𝐴 − 1 = [ ˆ 𝑎 1 , 1 ˆ 𝑣 𝑇 ˆ 𝑢 ˆ 𝐵 ] A = [ a 1 , 1 v T u B ] A − 1 = [ a ^ 1 , 1 v ^ T u ^ B ^ ] 并且 ˆ 𝑎 1 , 1 ≠ 0 a ^ 1 , 1 ≠ 0
𝐵 − 1 = ˆ 𝐵 − ˆ 𝑢 ˆ 𝑣 𝑇 ˆ 𝑎 1 , 1 B − 1 = B ^ − u ^ v ^ T a ^ 1 , 1 定理中描述的是消去第一行第一列的情况.实际上,它可以非常显然地推广到消去任意一行一列的情况,因此我们只需在算法最开始计算一次 ˜ 𝐴 − 1 A ~ − 1 𝑂 ( 𝑛 2 ) O ( n 2 )
描述有些抽象,可以参考 C++ 代码 1
2
3
4
5
6
7
8
9
10
11
12
13
14 void eliminate ( int A [][ MAXN ], int r , int c ) { // 消去第 r 行第 c 列
row_marked [ r ] = col_marked [ c ] = true ; // 已经被消掉
int inv = quick_power ( A [ r ][ c ], p - 2 ); // 逆元
for ( int i = 1 ; i <= n ; i ++ )
if ( ! row_marked [ i ] && A [ i ][ c ]) {
int tmp = ( long long ) A [ i ][ c ] * inv % p ;
for ( int j = 1 ; j <= n ; j ++ )
if ( ! col_marked [ j ] && A [ r ][ j ])
A [ i ][ j ] = ( A [ i ][ j ] - ( long long ) tmp * A [ r ][ j ]) % p ;
}
}
总共要做 𝑛 2 n 2 𝑂 ( 𝑛 2 ) O ( n 2 ) 𝑂 ( 𝑛 3 ) O ( n 3 )
构造最大匹配 我们刚刚已经解决了构造一组完美匹配的问题,但是求解问题时一般需要最大匹配.
前面已经提到,𝐺 G r a n k ˜ 𝐴 rank A ~ ˜ 𝐴 A ~ 𝐺 G
换一个角度考虑,如果 𝐺 G ˜ 𝐴 A ~ ˜ 𝐴 A ~ ˜ 𝐴 A ~ ˜ 𝐴 A ~ ˜ 𝐴 A ~
求出最大满秩子方阵之后,再用上面的算法找出导出子图的一组完美匹配,即可得到原图的一组最大匹配.注意由于高斯消元中可能会有行的交换,因此实现时要注意维护好点的编号.
UOJ #79. 一般图最大匹配 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137 #include <cstring>
#include <iostream>
#include <random>
#include <utility>
using namespace std ;
constexpr int MAXN = 505 , p = ( int ) 1e9 + 7 ;
int qpow ( int a , int b ) {
int ans = 1 ;
while ( b ) {
if ( b & 1 ) ans = ( long long ) ans * a % p ;
a = ( long long ) a * a % p ;
b >>= 1 ;
}
return ans ;
}
int A [ MAXN ][ MAXN ], B [ MAXN ][ MAXN ], t [ MAXN ][ MAXN ], id [ MAXN ];
// 高斯消元 O(n^3)
// 在传入 B 时表示计算逆矩阵, 传入 nullptr 则只需计算矩阵的秩
void Gauss ( int A [][ MAXN ], int B [][ MAXN ], int n ) {
if ( B ) {
memset ( B , 0 , sizeof ( t ));
for ( int i = 1 ; i <= n ; i ++ ) B [ i ][ i ] = 1 ;
}
for ( int i = 1 ; i <= n ; i ++ ) {
if ( ! A [ i ][ i ]) {
for ( int j = i + 1 ; j <= n ; j ++ )
if ( A [ j ][ i ]) {
swap ( id [ i ], id [ j ]);
for ( int k = i ; k <= n ; k ++ ) swap ( A [ i ][ k ], A [ j ][ k ]);
if ( B )
for ( int k = 1 ; k <= n ; k ++ ) swap ( B [ i ][ k ], B [ j ][ k ]);
break ;
}
if ( ! A [ i ][ i ]) continue ;
}
int inv = qpow ( A [ i ][ i ], p - 2 );
for ( int j = 1 ; j <= n ; j ++ )
if ( i != j && A [ j ][ i ]) {
int t = ( long long ) A [ j ][ i ] * inv % p ;
for ( int k = i ; k <= n ; k ++ )
if ( A [ i ][ k ]) A [ j ][ k ] = ( A [ j ][ k ] - ( long long ) t * A [ i ][ k ]) % p ;
if ( B ) {
for ( int k = 1 ; k <= n ; k ++ )
if ( B [ i ][ k ]) B [ j ][ k ] = ( B [ j ][ k ] - ( long long ) t * B [ i ][ k ]) % p ;
}
}
}
if ( B )
for ( int i = 1 ; i <= n ; i ++ ) {
int inv = qpow ( A [ i ][ i ], p - 2 );
for ( int j = 1 ; j <= n ; j ++ )
if ( B [ i ][ j ]) B [ i ][ j ] = ( long long ) B [ i ][ j ] * inv % p ;
}
}
bool row_marked [ MAXN ] = { false }, col_marked [ MAXN ] = { false };
int sub_n ; // 极大满秩子矩阵的大小
// 消去一行一列 O(n^2)
void eliminate ( int r , int c ) {
row_marked [ r ] = col_marked [ c ] = true ; // 已经被消掉
int inv = qpow ( B [ r ][ c ], p - 2 );
for ( int i = 1 ; i <= sub_n ; i ++ )
if ( ! row_marked [ i ] && B [ i ][ c ]) {
int t = ( long long ) B [ i ][ c ] * inv % p ;
for ( int j = 1 ; j <= sub_n ; j ++ )
if ( ! col_marked [ j ] && B [ r ][ j ])
B [ i ][ j ] = ( B [ i ][ j ] - ( long long ) t * B [ r ][ j ]) % p ;
}
}
int vertices [ MAXN ], girl [ MAXN ]; // girl 是匹配点, 用来输出方案
int main () {
cin . tie ( nullptr ) -> sync_with_stdio ( false );
auto rng = mt19937 ( random_device {}());
int n , m ;
cin >> n >> m ; // 点数和边数
while ( m -- ) {
int x , y ;
cin >> x >> y ;
A [ x ][ y ] = rng () % p ;
A [ y ][ x ] = - A [ x ][ y ]; // Tutte 矩阵
}
for ( int i = 1 ; i <= n ; i ++ )
id [ i ] = i ; // 输出方案用的,因为高斯消元的时候会交换列
memcpy ( t , A , sizeof ( t ));
Gauss ( A , nullptr , n );
for ( int i = 1 ; i <= n ; i ++ )
if ( A [ id [ i ]][ id [ i ]]) vertices [ ++ sub_n ] = i ; // 找出一个极大满秩子矩阵
for ( int i = 1 ; i <= sub_n ; i ++ )
for ( int j = 1 ; j <= sub_n ; j ++ ) A [ i ][ j ] = t [ vertices [ i ]][ vertices [ j ]];
Gauss ( A , B , sub_n );
for ( int i = 1 ; i <= sub_n ; i ++ )
if ( ! girl [ vertices [ i ]])
for ( int j = i + 1 ; j <= sub_n ; j ++ )
if ( ! girl [ vertices [ j ]] && t [ vertices [ i ]][ vertices [ j ]] && B [ j ][ i ]) {
// 注意上面那句 if 的写法, 现在 t 是邻接矩阵的备份,
// 逆矩阵 j 行 i 列不为 0 当且仅当这条边可行
girl [ vertices [ i ]] = vertices [ j ];
girl [ vertices [ j ]] = vertices [ i ];
eliminate ( i , j );
eliminate ( j , i );
break ;
}
cout << sub_n / 2 << '\n' ;
for ( int i = 1 ; i <= n ; i ++ ) cout << girl [ i ] << ' ' ;
return 0 ;
}
习题 参考资料 Mucha M, Sankowski P.Maximum matchings via Gaussian elimination 周子鑫,杨家齐《基于线性代数的一般图匹配》 ZYQN 《基于线性代数的一般图匹配算法》 2026/1/7 08:56:54 ,更新历史 在 GitHub 上编辑此页! H-J-Granger , Tiphereth-A , Ir1d , StudyingFather , countercurrent-time , Early0v0 , NachtgeistW , 310552025atNYCU , CCXXXI , Enter-tainer , AngelKitty , antileaf , cjsoft , diauweb , ezoixx130 , GekkaSaori , HeliumOI , Henry-ZHR , Konano , LovelyBuggies , Makkiy , mgt , minghu6 , P-Y-Y , PotassiumWings , pukui , SamZhangQingChuan , ShizuhaAki , sshwy , Suyun514 , weiyong1024 , Xeonacid , yusancky , accelsao , AntiLeaf , GavinZhengOI , Gesrua , ksyx , kxccc , lychees , Peanut-Tang , SukkaW CC BY-SA 4.0 和 SATA